
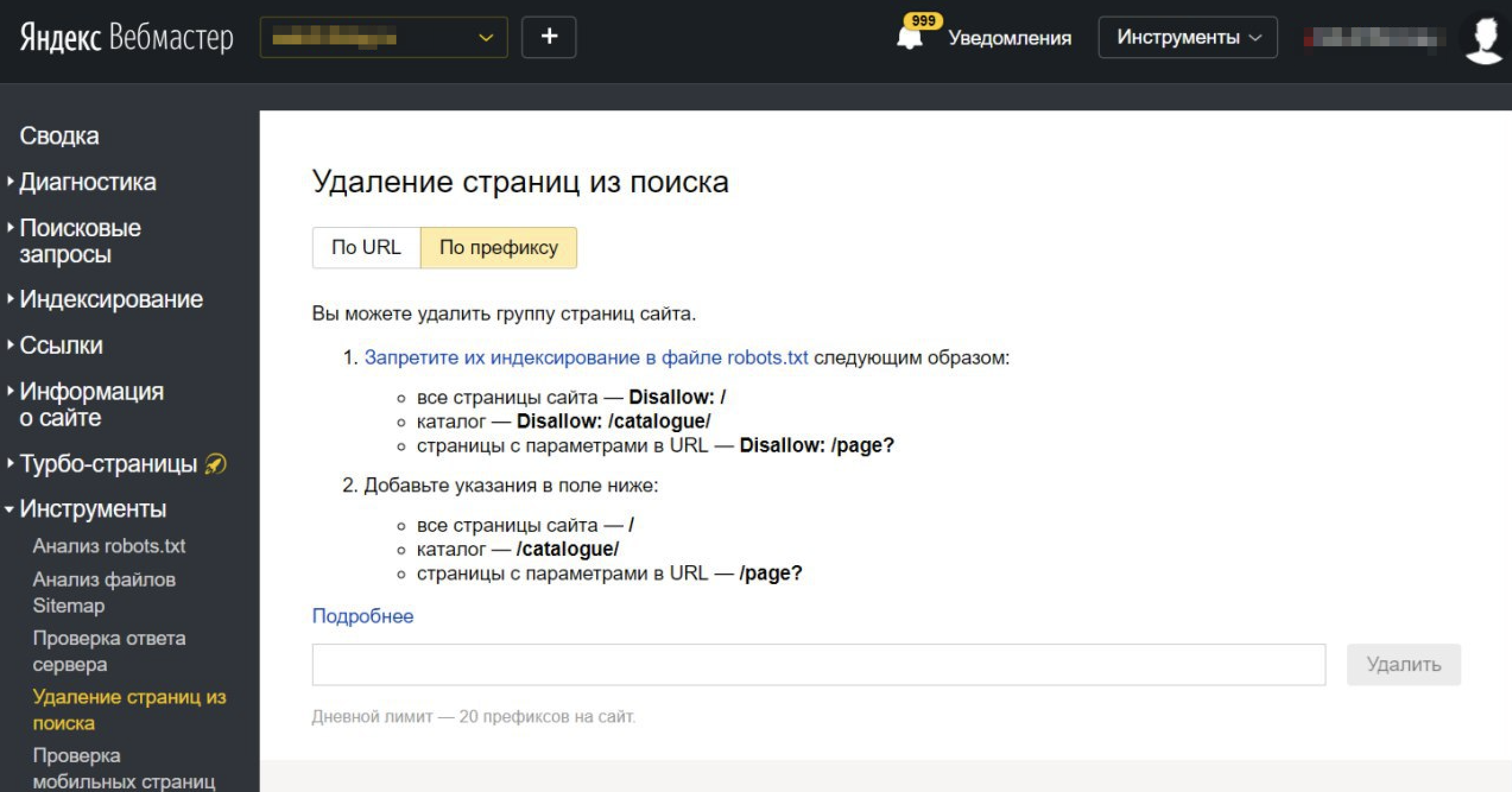
Порой возникают ситуации, когда из Поиска нужно быстро удалить большой объем данных: весь сайт, целый раздел или страницы с параметром. Теперь сделать это стало легко, так как сегодня мы доработали функциональность «Удалить URL»: в инструменте появилась возможность удалять страницы сайта по префиксу при условии, что этот запрет реализован и в robots.txt.
Так, если ввести в поле адрес сайта
http://example.com/
то это будет означать, что весь сайт нужно удалить из поиска.
А если ввести только раздел, например, вот так:
http://example.com/catalogue/
то из поиска нужно удалить все страницы этого раздела.
Наконец, если вам мешают страницы с параметрами в URL, например, после символа?, то укажите
http://example.com/page?
чтобы они пропали из поиска. При этом, конечно, не забудьте продублировать запрет в robots.txt, иначе команда не сработает. Указывать можно как абсолютные, так и относительные пути, как и в robots.txt.
Через несколько часов после использования инструмента указанные страницы должны будут пропасть из поиска. Чтобы вернуть раздел обратно в Поиск, его нужно будет снова разрешить к индексированию в robots.txt, и отправить на переобход.
Читатели нашего блога, скорее всего, не раз встречали пожелания о таком инструменте в комментариях, и мы рады, что смогли воплотить эти пожелания в реальный инструмент.
Команда Вебмастера
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен